머신러닝과 딥러닝 모델을 성공적으로 학습시키기 위해서는 데이터 전처리 과정이 필수적입니다. 🌟 특히, 모델이 이해할 수 있는 형태로 데이터를 변환하는 작업은 모델의 성능을 크게 좌우합니다. 이 중에서도 'One-Hot Encoding'은 범주형 데이터를 다룰 때 가장 널리 사용되는 기법 중 하나입니다. 📊

One-Hot Encoding의 정의와 필요성 📚
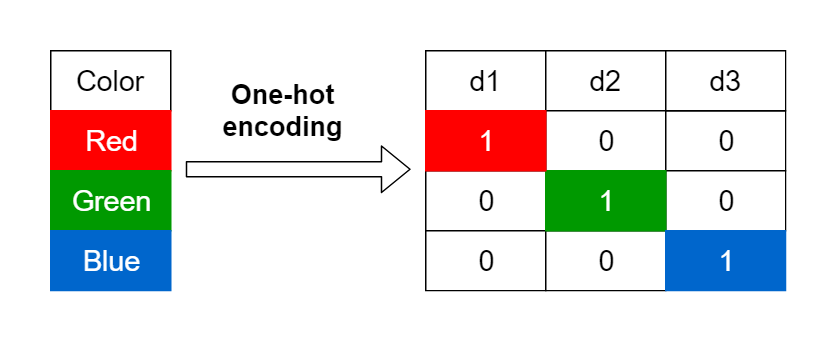
One-Hot Encoding은 범주형 변수를 처리하는 방법으로, 각 범주를 독립적인 이진 변수로 변환합니다. 예를 들어, '색상'이라는 범주형 변수가 '빨강', '녹색', '파랑'의 세 가지 값을 가질 때, 이를 세 개의 이진 변수로 나누어 각각 '빨강=1, 녹색=0, 파랑=0'과 같이 표현하는 것입니다. 🎨
One-Hot Encoding의 장점
- 모델 호환성: 대부분의 머신러닝 알고리즘은 숫자형 데이터를 요구하기 때문에, 범주형 데이터를 적절히 숫자형으로 변환해야 합니다.
- 의미적 분리: 각 범주를 독립적인 특성으로 변환함으로써, 범주 사이의 순서나 거리가 없다는 점을 모델에 명확하게 전달할 수 있습니다.
One-Hot Encoding의 단점과 주의점 ⚠️
- 차원의 저주: 범주의 수가 많을 경우, 데이터의 차원이 급격히 증가하여 모델의 복잡도가 증가하고, 과적합(overfitting)의 위험이 높아집니다.
- 희소성: 대부분의 값이 0인 희소 행렬이 생성되며, 이는 메모리 사용량 증가와 계산 효율성 감소를 초래할 수 있습니다.
One-Hot Encoding은 범주형 데이터를 머신러닝 모델이 이해할 수 있는 형태로 변환하는 효율적인 방법입니다. 🚀 그러나 차원의 저주와 희소성 문제를 고려하여, 필요한 경우 차원 축소 기법과 함께 사용하거나, 대안적인 인코딩 방법을 고려하는 것이 좋습니다. 데이터 전처리 과정에서 One-Hot Encoding을 올바르게 사용한다면, 더 정확하고 효율적인 모델 학습이 가능할 것입니다. 데이터 과학자와 머신러닝 엔지니어에게 One-Hot Encoding은 강력한 도구이며, 그 사용법을 정확히 이해하는 것이 중요합니다. 🌟
'데이터사이언스(Data Science) > ML & DL' 카테고리의 다른 글
| [A/B Testing] Interrupted Time Series (ITS) 분석: 변화를 이해하는 강력한 도구 🚀 (9) | 2024.02.17 |
|---|---|
| [Deep Learning ]Sparse Categorical Crossentropy: 효율적인 멀티클래스 분류를 위한 손실 함수 (16) | 2024.02.16 |
| [Deep Learning] 크로스 엔트로피(Cross Entropy)의 이해와 비교 분석 🔍 (18) | 2024.02.14 |
| [Deep Learning] 딥러닝에서의 핵심 요소, 활성화 함수(Activation Function) 🌟 (35) | 2024.02.13 |
| [Deep Learning] 신경망(Neural Networks): 인공지능의 뇌를 이해하기 🧠💡 (10) | 2024.02.12 |



