안녕하세요! 오늘은 AI와 딥러닝의 중요한 논문인 "Attention Is All You Need"에 대해 쉽게 설명해드리겠습니다. 이 논문은 2017년에 Google Brain 팀이 발표한 것으로, 딥러닝에서 사용하는 모델인 Transformer를 소개합니다. 🤖📚

1. 문제점 해결 💡
이전에는 기계 번역이나 텍스트 생성과 같은 작업에 주로 **순환 신경망(RNN)**이나 LSTM(Long Short-Term Memory) 모델이 사용되었습니다. 하지만 이런 모델들은 다음과 같은 문제점이 있었습니다:
- 연산 속도 느림: RNN과 LSTM은 순차적으로 데이터를 처리하기 때문에 병렬 처리가 어렵습니다.
- 긴 문장 처리 어려움: 긴 문장에서 멀리 떨어진 단어들 간의 관계를 이해하는 데 어려움을 겪습니다.
2. Transformer 모델의 등장 🚀
"Attention Is All You Need" 논문은 이러한 문제를 해결하기 위해 Transformer 모델을 제안했습니다. 이 모델은 다음과 같은 특징이 있습니다:
- 병렬 처리 가능: 데이터를 한꺼번에 처리할 수 있어서 연산 속도가 빠릅니다.
- Self-Attention 메커니즘 사용: 문장의 모든 단어들이 서로 어떻게 관련되어 있는지 학습합니다.
3. Self-Attention 메커니즘 🧠
Self-Attention은 Transformer 모델의 핵심 아이디어입니다. 쉽게 말해서, 문장 내의 각 단어가 다른 모든 단어와 어떻게 관련되어 있는지를 계산합니다. 예를 들어, "The cat sat on the mat"이라는 문장에서 "cat"은 "sat"와 "mat"와 강하게 관련되어 있을 것입니다. Self-Attention 메커니즘은 이런 관계를 학습하여 더 나은 문맥 이해를 가능하게 합니다.
4. Transformer의 구조 🏗️
Transformer 모델은 **인코더(Encoder)**와 **디코더(Decoder)**로 구성되어 있습니다:
- 인코더: 입력 문장을 받아서 내부 표현(벡터)을 만듭니다. 이 과정에서 Self-Attention 메커니즘을 사용합니다.
- 디코더: 인코더가 만든 내부 표현을 받아서 출력 문장(예: 번역된 문장)을 만듭니다.
Transformer 모델은 자연어 처리 작업에서 주로 사용되는 딥러닝 모델로, 인코더(Encoder)와 디코더(Decoder)로 구성됩니다. 여기에서는 인코더와 디코더의 구조와 동작을 순서대로 자세히 설명하겠습니다. 🤖
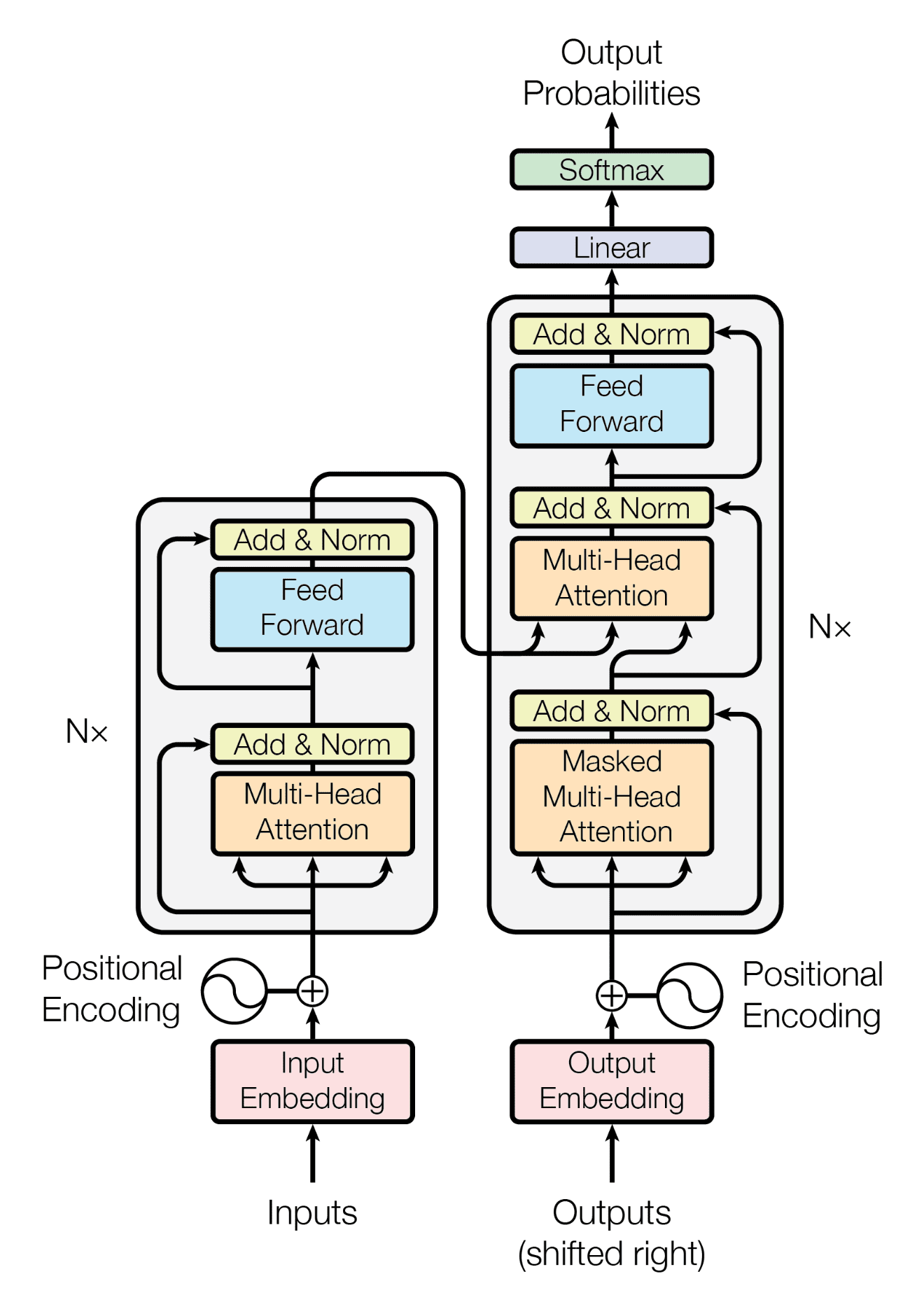
인코더(Encoder) 🏗️
Transformer의 인코더는 입력 문장을 벡터 표현으로 변환하는 역할을 합니다. 인코더는 여러 개의 동일한 레이어로 구성되어 있으며, 각 레이어는 두 가지 주요 부분으로 나뉩니다: Self-Attention 메커니즘과 피드 포워드 신경망(Feed-Forward Neural Network).
1. 임베딩 레이어 (Embedding Layer) 📥
입력 단어들을 고차원 벡터로 변환합니다. 각 단어는 고유한 벡터로 표현되며, 이 벡터는 학습 과정에서 업데이트됩니다.
입력 문장: "The cat sat on the mat."
임베딩 벡터: [V1, V2, V3, V4, V5, V6]
2. 포지셔널 인코딩 (Positional Encoding) ⌛
Transformer는 순차적인 구조가 없기 때문에, 위치 정보를 추가하여 단어의 순서를 학습할 수 있게 합니다. 포지셔널 인코딩은 각 단어 벡터에 위치 정보를 더하는 방식으로 이루어집니다.
포지셔널 인코딩 추가 후: [V1+P1, V2+P2, V3+P3, V4+P4, V5+P5, V6+P6]
3. Self-Attention 메커니즘 🧠
입력된 단어 벡터들이 서로 어떻게 관련되어 있는지를 학습합니다. Self-Attention은 다음과 같은 과정을 거칩니다:
- 쿼리(Query), 키(Key), 밸류(Value) 벡터 생성: 입력 벡터를 선형 변환하여 Q, K, V 벡터를 만듭니다.
- 어텐션 스코어 계산: Q와 K 벡터의 내적(dot product)을 계산하고, 결과를 소프트맥스(Softmax) 함수에 통과시켜 각 단어의 중요도를 결정합니다.
- 가중합: V 벡터에 어텐션 스코어를 곱하여 중요한 단어의 정보를 강조합니다.
Self-Attention Output: [A1, A2, A3, A4, A5, A6]
4. 피드 포워드 신경망 (Feed-Forward Neural Network) 🔄
Self-Attention의 출력을 입력으로 받아, 각 단어 벡터에 독립적으로 적용되는 완전 연결층을 통과시킵니다.
FFNN Output: [F1, F2, F3, F4, F5, F6]
5. 잔차 연결과 정규화 (Residual Connection and Layer Normalization) 🔁
각 레이어의 출력을 입력과 더하고, 레이어 정규화를 적용하여 학습을 안정화시킵니다.
Output after Residual and Layer Normalization: [E1, E2, E3, E4, E5, E6]
이 과정이 인코더 레이어 수만큼 반복됩니다.
디코더(Decoder) 🏗️
디코더는 인코더의 출력을 받아 최종 출력(예: 번역된 문장)을 생성합니다. 디코더도 여러 레이어로 구성되어 있으며, 각 레이어는 다음과 같은 부분으로 나뉩니다: Masked Self-Attention, 인코더-디코더 어텐션, 피드 포워드 신경망.
1. 임베딩 레이어 (Embedding Layer) 📥
입력된 타겟 단어들을 고차원 벡터로 변환합니다.
타겟 문장: "The cat sat."
임베딩 벡터: [T1, T2, T3]
2. 포지셔널 인코딩 (Positional Encoding) ⌛
위치 정보를 더하여 순서 정보를 포함합니다.
포지셔널 인코딩 추가 후: [T1+P1, T2+P2, T3+P3]
3. Masked Self-Attention 🧠
타겟 단어들 간의 관계를 학습합니다. 이 때, 미래의 단어를 참조하지 못하도록 마스크를 사용합니다.
Masked Self-Attention Output: [M1, M2, M3]
4. 인코더-디코더 어텐션 (Encoder-Decoder Attention) 🔗
인코더의 출력과 디코더의 출력을 결합하여 입력 문장과 타겟 문장 간의 관계를 학습합니다.
Encoder-Decoder Attention Output: [D1, D2, D3]
5. 피드 포워드 신경망 (Feed-Forward Neural Network) 🔄
Self-Attention의 출력을 입력으로 받아, 각 단어 벡터에 독립적으로 적용되는 완전 연결층을 통과시킵니다.
FFNN Output: [F1, F2, F3]
6. 잔차 연결과 정규화 (Residual Connection and Layer Normalization) 🔁
각 레이어의 출력을 입력과 더하고, 레이어 정규화를 적용하여 학습을 안정화시킵니다.
Output after Residual and Layer Normalization: [O1, O2, O3]
7. 최종 출력 (Final Output) 📤
디코더의 최종 출력은 소프트맥스 레이어를 통과하여, 각 단어에 대한 확률 분포를 생성합니다. 이 확률 분포에서 가장 높은 확률을 가진 단어가 최종 출력으로 선택됩니다.
Transformer 모델의 인코더는 입력 문장을 벡터 표현으로 변환하고, 디코더는 이 벡터 표현을 받아 최종 출력을 생성합니다. Self-Attention 메커니즘을 통해 문장 내 단어 간의 관계를 학습하며, 병렬 처리가 가능하여 빠른 연산 속도를 자랑합니다. 이 모델은 다양한 자연어 처리 작업에서 뛰어난 성능을 보이며, 현재 많은 AI 응용 프로그램에서 사용되고 있습니다.
'AI 개발 > LLM' 카테고리의 다른 글
| [LLM] 📊 Base LLM vs Instruction-Tuned LLM (1) | 2024.06.15 |
|---|---|
| [Transformer] 트랜스포머 포지셔널 인코딩 (Positional Encoding) 쉽게 설명하기 📏 (3) | 2024.05.30 |
| [LLM] 정보 검색(Information Retrieval): 디지털 세계의 나침반 🧭 (62) | 2024.03.08 |
| [LLM] 🌟 Few-Shot Learning, Zero-Shot Learning, Decomposition, Ensembling: 차이점 비교 (65) | 2024.03.07 |
| [LLM] Prompt Engineering 프롬프트 엔지니어링: 초보자를 위한 가이드 🌟 (62) | 2024.03.06 |



